Till skillnad från nyhetsbrev tog KOD-listan inget sommaruppehåll. Där har det diskuterats digitala skärmar i utställningar, publicering av inskannade årsböcker, hur man kan gå till väga för att byta från Microsofts tjänster, verktyg för OCR-tolkning, AI-genererade bildbeskrivningar i museisamlingar – och såklart GDPR.
Till detta nyhetsbrev har vi inte skrivit några egna artiklar. Istället kommer här några tips på intressant läsning om digitalt kulturarv som vi snappat upp i andra sammanhang.
I senaste numret av Nordisk Museologi skriver Cecilia Bygdell, forskare vid Upplandsmuseet, om Samtida digitala insamlingspraktiker. Kvantitet, kris och demokratiska museer. Artikeln är en uppmaning till kritisk reflektion kring varför och hur museer genomför storskaliga digitala insamlingsprojekt/samtidsdokumentationer, väl värd att läsa för alla som arbetar med webbenkäter och digital insamling.
Under sommaren har teamet runt CommonsDB publicerat sin första genomförbarhetsanalys. Projektets mål är att bygga ett register över upphovsrättsfria och öppet licenserade verk. Prototypen finansieras av EU-kommissionen.
Vasamuseet har testat en AI-uppläst audioguide i Vasamuseets trädgård över sommaren. Läs pressmeddelandet eller lyssna på audioguiden (som konstigt nog ligger på Järnvägsmuseets webbplats, inte Vasamuseets). Författaren Brian Merchant har pratat med översättare som förlorat jobbet på grund av AI – det kanske är just översättare och röstskådespelare som blir först med att tappa sina museiuppdrag på grund av AI?
A propå audioguider: Konsultföretaget Nubart har tagit fram en analys av museiappar. Enligt deras uppskattning och analys av nedladdningsstatistik laddar bara 2,47 % av besökarna ned museernas egna appar. Det vore spännande att höra från ett svenskt museum som har utvärderat sin app – hör gärna av dig om du vill bidra med ditt perspektiv till nästa nyhetsbrev!
🗓️ Digikult 2025 går av stapeln i Västerås den 14–16 oktober. Istället för att anordnas i Göteborg kommer konferensen att rotera mellan olika svenska städer och Västerås (med medarrangörerna Västerås konstmuseum och Västmanlands länsmuseum) är alltså först ut.
🗓️ GLAMWiki 2025. Wikimedia-rörelsens konferens om kulturarv äger rum den 30 oktober till 1 november i Lissabon, Portugal. Temat är ”Resilience. Shaping the Future Through Community and Openness”.
🗓️ Fantastic Futures 2025. AI4LAMs årliga konferens har i år temat “AI Everywhere, All at Once” och äger rum 3–5 december på British Library och delvis digitalt.
I många utställningar används digitala skärmar för att erbjuda fördjupad information, multimedialt innehåll eller målgruppsanpassade upplevelser. Samtidigt behöver vi tänka på frågor om tillgänglighet, teknikens livslängd och besökarnas faktiska engagemang. Är skärmar en väg till ökad delaktighet och kunskap – eller riskerar de att bli dyra, svåråtkomliga lösningar? I den här artikeln fördjupar jag mig i både möjligheter och utmaningar med digitala gränssnitt i fysiska utställningar, med utgångspunkt i ett pågående samtal mellan två kollegor.
Ett omdebatterat ämne
Förra veckan dök en fråga upp i mejlinglistan till detta nyhetsbrev, KOD-listan. Jesper Hillbom beskrev ett kommande utställningsprojekt där museet överväger att visa föremålsinformation och bilder via Digitalt museums API på pekskärmar vid montrarna – en idé som väckt intern tveksamhet kring tillgänglighet och användarvänlighet. I ett svar lyfte Fredrik Nordbladh en rad fördelar med digitala skärmar: de är flexibla, kan anpassas efter olika målgrupper och möjliggör ett rikare innehåll, såsom film, 3D-modeller och olika tillgänglighetsformat som syntolkning, teckenspråk och lättläst. Samtidigt pekar han på tydliga nackdelar: tekniken kräver löpande underhåll, både tekniskt och innehållsmässigt, samt kan vara energikrävande och kostsam att utveckla på ett tillgängligt sätt. Dessutom upplever många besökare skärmtrötthet, och säkerhetsrisker som intrång i system har förekommit. Utifrån tidigare projekt inom besöksnäringen betonar Fredrik också vikten av att tänka strategiskt kring den digitala upplevelsens mervärde, snarare än att fokusera enbart på själva tekniken.
Mejlkonversationen triggade olika tankar hos mig (och om det gör det hos dig med, delta gärna i diskussionen i mejllistan eller kommentera under detta inlägg).
Det blir inte automatiskt bättre med skärmar
Tyvärr har jag sett flera exempel där skärmarna inte har förbättrat utställningar, utan tvärtom. I vissa fall har det försämrat utställningsupplevelsen. Jag tänker på de fall, där skärmarna har lett till att all text som curatorerna eller antikvarierna har velat få med fick vara med. Begränsningen som av naturliga skäl finns för fysiska texter på grund av en begränsad väggyta har också fördelar. Den bästa utställningstexten är ändå den där flera tillsammans slipar på ordval, formuleringar, väljer ut och prioriterar till en text har tagit form.
Den naturliga begränsningen finns inte med utställningsskärmar och det är både en för- och ibland en nackdel. Texterna till skärmar både produceras med samma noggrannhet som fysiska texter på väggarna, vi borde producera dem med samma kvalitetsanspråk som vi har på alla andra utställningstexter.
Samma ambivalens ligger i skärmarnas potential att uppdateras, på ett mycket enklare sätt än väggtexter eller utställningskataloger. Det kan lätt bli ett ”Vi gör det först såhär, invigningen är ju snart, och då uppdaterar vi skärmen senare” – men senare blir aldrig av.
När jag som de flesta i sektorn rör mig i utställningar är jag ju lite yrkesskadad och observerar andra besökare. Här kommer mina rekommendationer vad som kan vara bra att tänka på om man funderar på att använda skärmar i utställningar – och när man kanske ska låta bli.
1. Det beror på utställningen.
Det är en stor skillnad om man gestaltar skärmar för en tillfällig eller en permanent utställning. Förväntningarna på tekniken, både när det gäller hårdvara och mjukvara, är helt olika. Planerar man för en basutställning som ska stå fem, tio eller tjugo år behöver man räkna in att mjukvaran behöver uppdateras eller ersättas och att hårdvaran med stor sannolikhet behöver ersättas med tiden. Det krävs en helt annan planering av kompetens som man behöver internt för att kunna agera snabbt. Vi alla vet att inget är så pinsamt som en stor pekskärm med en klisterlapp på: ”Ur funktion”. Samtidigt måste man räkna in att användarupplevelsen och besökarnas förväntningar kommer förändras med tiden. En animerad film, ett interaktivt spel eller till och med ett bildspel kan upplevas som otroligt gammaldags om fem till tio år. En utställning som känns toppmodern när den invigs kan snabbt upplevas som utdaterad om bara några år. Har ni den typen av budget för att förvalta och uppdatera tekniken? Vet ni att det finns den interna kompetensen för att förvalta, uppdatera utställningstekniken och planera för utbyte och uppgraderingar?
2. Att kunna dra till sig besökarnas nyfikenhet – och ge ett direkt svar på den.
Ett stort problem som jag har upplevt i många utställningar är att besökarna ser något, till exempel ett föremål i en monter, och är nu, i den sekunden, intresserad av vad det är för något. De har helt enkelt ett direkt intresse av att få information. De ser ingenting som ger dem svaret i den fysiska omgivningen, förutom en skärm – och den kommunicerar alldeles för otydligt vad de får förvänta sig från att interagera med dem.
Jag kan varmt rekommendera boken UI is communication : how to design intuitive, user-centered interfaces by focusing on effective communication som jag nyss läste i en kurs om användarvänliga digitala gränssnitt. Den sammanfattar väldigt pedagogiskt och icke-tekniskt viktiga grundprinciper för användargränssnitt och deras formgivning. I alla fall gav den mig en formulering för just detta problem och hur induktiva användargränssnitt (user interfaces på engelska, förkortad UI) undviker det: ”Inductive UIs explain each task step with a clear and concise main instruction that answers the first question users have: What am I supposed to do here?” (McKay 2013, p. 39)
Många utställningsskärmar är gestaltade på ett sätt som satsar på experiment istället för att göra interaktionsflödet självklart. Besökaren behöver testa sig fram, hittar inte direkt knappar för att de finns på platser där de inte förväntar sig dem eller för att de använder andra ikoner än de är vana vid. Då dör det där momentära intresset som besökaren hade otroligt fort. Där hade vi en möjlighet för kunskapsförmedling och har misslyckats.
3. Mäta framgångar och upptäcka nödvändiga uppdateringar
Ett stort problem är att det, enligt min kunskap, finns alldeles för lite data och för få utvärderingar av utställningsskärmar, både för tillfälliga och basutställningar. Därför är det en fråga jag rekommenderar om ni vill upphandla eller köpa in ett system till digital förmedling i fysiska miljöer: Hur lätt är det att ta fram statistik om användning? Vilken sorts statistik kan vi samla in, hur får vi tillgång till datan?
Ni kan såklart också göra kvalitativa undersökningar med besökarna. Jag kan varmt rekommendera att prata med besökare i olika demografiska kategorier innan och efter utställningsbesöket. Då får man ofta fram mycket överraskande och lärorik information om användandet av digitala förmedlingsstationer i form av skärmar, ljudspår och liknande.
Ifall ni kan utvärdera statistik är det också viktigt att tänka på vad siffrorna egentligen betyder: En skärm som används sällan, men då väldigt länge och på många olika hierarkiska nivåer kan vara mer meningsfull för en viss målgrupp än en skärm som används otroligt ofta, men bara i några få sekunder. Den ena kan vara en station för besökare som är intresserad av fördjupning, som besöker utställningen själv och har mycket tid, medan den andra kan stå centralt och verkar ha ett tydligt syfte, men är sedan svårt att interagera med. Jag har upplevt att det oftast bara går att tyda datan om man kombinerar statistiska analyser med observationer i utställningar och kvalitativa användarintervjuer.
4. Testa användarupplevelsen innan lanseringen
I museisektorn satsar man ofta på en stor lansering, till exempel vid en utställningsinvigning. Jag avråder dock från att göra samma sak för digitala användarupplevelser. Även om det bara finns lite tid kvar rekommenderar jag att prioritera användartester. Det kan vara så enkelt att be olika kollegor från olika generationer, med olika nivåer av utställningsvana, att testa prototypen. Ge dem inga eller få anvisningar (för det kommer de flesta besökarna inte heller ha i utställningen) och observera hur väl kollegan tar sig genom formatet. Är det tydligt vad som förväntas av besökaren? Letar din kollega länge efter olika knappar? Undrar den överlag varför hen ska interagera med skärmen?
5. En skärm är ingen bok, eller: Dra nytta av mediets möjligheter!
Av de skärmar jag själv har utvecklat är det de som antingen löser ett riktigt problem för besökaren eller som erbjuder verklig interaktion som används mest. Det ser jag bekräftat i mina observationer i andra utställningar.
Många utställningsskärmar är en animerad version av en klassisk utställningstext eller en katalog. Det är text med bild, bildspel med text, text med mera text. Det förutsätter a) att besökaren vill fördjupa sig här och nu i längre texter och b) att andra besökare som står runt omkring vill läsa exakt samma text samtidigt istället för andra texter som finns på samma skärm. Problemet som besökaren har är dock ofta inte ”Nu vill jag läsa mer”, utan snarare ”Vad är det där? Varför var det sådär?” och ”Jag vill komma närmare! Jag vill veta mer om just detta!” Många utställningsskärmar har svårt att bemöta den konkreta frågan och bemöter besökaren istället med text som kan vara svårt att navigera och söka i efter den relevanta informationen.
Jag tyckte mycket om de föremålsbaserade små skärmarna i Historiska museets utställning ”Vikingarnas värld” (även tillgängliga på webben), där man kan zooma in på föremålen, se dem från olika håll och läsa mer om dem. Skärmarna löste direkt flera problem som fysiska föremål har i utställningar: ofta kan man inte komma riktigt nära och man ser dem bara från ett håll. Dessutom försökte man inte koppla en och samma skärm till många föremål i olika montrar, utan kopplingen mellan skärmen och föremålet blev väldigt tydlig.
Hur kan vi göra rätt?
Digitala skärmar i utställningar kan fördjupa upplevelsen, tillgängliggöra innehåll och skapa nya sätt att möta föremål, men kräver samtidigt genomtänkt formgivning, intern kompetensutveckling, resurser för förvaltning och en förståelse för olika målgruppers behov och beteenden. Som alltid gäller det att matcha teknikens möjligheter med utställningens syfte och publik. Hur har ni arbetat med digitala skärmar i era utställningar? Vilka lösningar har fungerat – och vilka har ni övergett? Dela gärna med er av era erfarenheter i mejllistan eller kommentera här!
Databasen Gotlandic Picture Stones (gotlandicpicturestones.se) lanserades den 25 april 2025. Sajten är tillkommen i ett flerårigt forskningsprojekt knutet till Stockholms universitet och Gotlands museum inom ramen för forskningsprogrammet Digarv. Alla kända gotländska bildstenar har dokumenterats i 3D med hjälp av fotogrammetri och varje bildsten presenteras på sajten med 3D-modell, metadata och bibliografi.
Webbplatsen är byggd i Omeka S, ett php-baserat CMS med öppen källkod förvaltat av Digital Scholar som bland annat tillhandahåller referensverktyget Zotero.
Kärnan i projektet är de noggranna 3D-avbildningarna. Fotograferingsprocessen är utförligt beskriven. Det står att 3D-modellerna är nedladdningsbara men jag hittar inte några nedladdningsknappar – antingen är de väl dolda eller så saknas de.
Själva digitiseringsprojektet har fått en hel del uppmärksamhet men jag tänkte istället titta närmare på en del vägval kring teknik och användargränssnitt. Det blir några noteringar kring länkstruktur, länkade öppna data, kartvyer och en del annat smått och gott.
Länkstruktur
Projektet använder Omeka S något styltiga urler. Startsidan ligger till exempel på adressen https://www.gotlandicpicturestones.se/s/index/page/homepage. Även bildstenarna har ett krångligt ”s/index/” i adressen som borde tagits bort, förslagsvis med Omeka-modulen Clean Url.
Tanken med den publicerade databasen är förstås att resultatet av den enorma arbetsinsatsen med 3D-fotografering av bildstenarna ska göras tillgängligt för fler än bara de medverkande forskarna. Det är glädjande att allt är öppet tillgängligt (open access) och inte låst bakom inloggning hos ett kommersiellt förlag, tyvärr fortfarande alltför vanligt i forskarvärlden.
Det saknas dock uppgifter om copyright – för text- och bildmaterial hade en tillåtande CC-licens varit lämplig och för metadata är det kutym att förtydliga vad som är tillgängligt med licensen CC0.
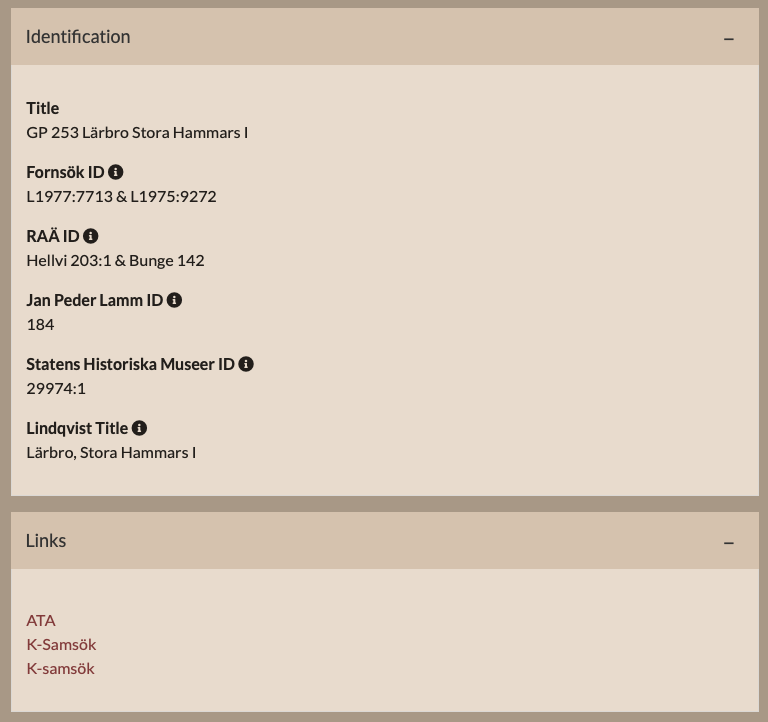
Alternativa identifierare för bildsten 2299. Skärmbild.
Nästa steg, som jag hoppas finns med i projektplanen framåt, skulle vara att lägga ytterligare fokus på sammanlänkning. En första ansats finns i fälten ”Identification” och ”Links”. Här uppenbarar sig dock problem direkt.
För det första: i bilden ovan saknas en viktig identifierare, nämligen den som används i själva databasen. Detta numeriska ID (såvitt jag kan bedöma ett autogenererat löpnummer inifrån Omeka-S, i exemplet ovan 2299) används i bildstenens URL men presenteras inte för användaren på något annat sätt.
För det andra: identifierarna är inte länkade. Om jag exempelvis vill hitta motsvarande bildsten i Statens Historiska Museers databas behöver jag klippa och klistra ”29974:1”, vilket tyvärr ger 250 999 träffar. Ingen större hjälp alltså. Tänk om den istället var länkad direkt till posten i SHMs samlingsdatabas. (Tyvärr drabbas bildstensprojektet här av SHMs databasbyte, där just formatet förvärvsnummer:löpnummer inte kan tolkas av fritextsöket).
Statens Historiska Museer ID finns som property på Wikidata, dock inte (såvitt jag kan bedöma) någon av de andra identifierarna. SHM ID handlar dessutom om uuid-strängen, för exempelstenen alltså object/BC48956B-6414-43B3-8191-C65506B0DF2A, inte 29974:1.
Här kan projektet alltså bidra med värdefull information till wikirörelsen för sammanlänkning av öppna data mellan olika plattformar. Hittills finns endast 21 bildstenar beskrivna på Wikidata, så en uppladdning av välstrukturerad, länkad information dit kommer göra stor skillnad.
Förkortningar – varför då?
Ibland märks det extra tydligt att projektmedlemmarna är vana vid att arbeta med tryckta texter, kanske särskilt uppslagsverk med begränsat utrymme. Helt i onödan har man nämligen valt att signera texter med författarnas initialer istället för att använda fullständiga namn. För att uttyda vem som är avsändare till en text behövs därmed en separat lista över förkortningar. I en digital publikation råder inte utrymmesbrist! Särskilt inte för så viktig information som vem som är en texts avsändare. Användningen av initialer gör det också betydligt krångligare att, exempelvis, söka fram alla texter författade av Anders Andrén. Projektet vill också att den som hänvisar till databasen ska använda författarnas fullständiga namn.
Ibland är förkortningsförvirringen dock inte forskningsprojektets fel. De anger till exempel att förkortningen SHM står för ”Statens Historiska Museum”, i vardagligt tal känt som Historiska museet. Numera har dock den överordnade myndigheten Statens Historiska Museer tagit över förkortningen och kallar sig för SHM – oklart vilken förkortning som blir kvar för själva museet. (Nuvarande SHM, det vill säga museimyndigheten, gick länge under förkortningen SHMM. Webbplatsen shmm.se är föredömligt omdirigerad).
Kartvyerna
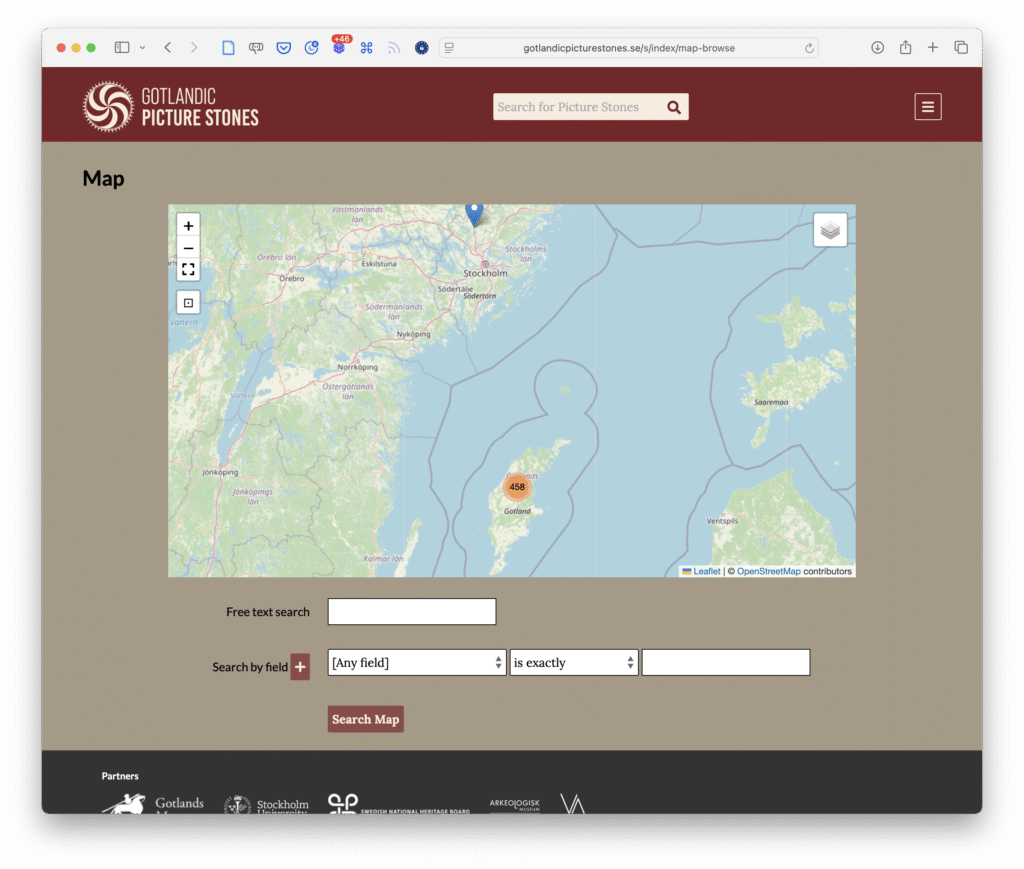
Den inledande kartvyn. Skärmbild.
Sajten använder Leaflet som kartverktyg. Leaflet innehåller nästintill oändliga möjligheter för anpassning och konfigurering. Några tillägg används (leaflet.markercluster för gruppering av kartnålar och leaflet-providers för att lägga till några alternativa kartlager) men i övrigt används verktyget utan särskilt många inställningar.
Särskilt grupperingen av kartnålar hade behövt tänkas och arbetas igenom ytterligare några varv. Den inledande kartvyn är automatiskt skalad till att innehålla samtliga kartnålar, men eftersom en bildsten visas på Historiska museet innebär det att kartan är såpass utzoomad att de övriga 458 bildstenarna klumpas ihop till en markör. Kanske hade någon slags chloroplethkarta på sockennivå passat på den utzoomade nivån för att vid inzoomning ersättas av markörer för varje bildsten? Det hade också varit bra med en livefiltrering av kartnålarna utifrån exempelvis titelfältet.
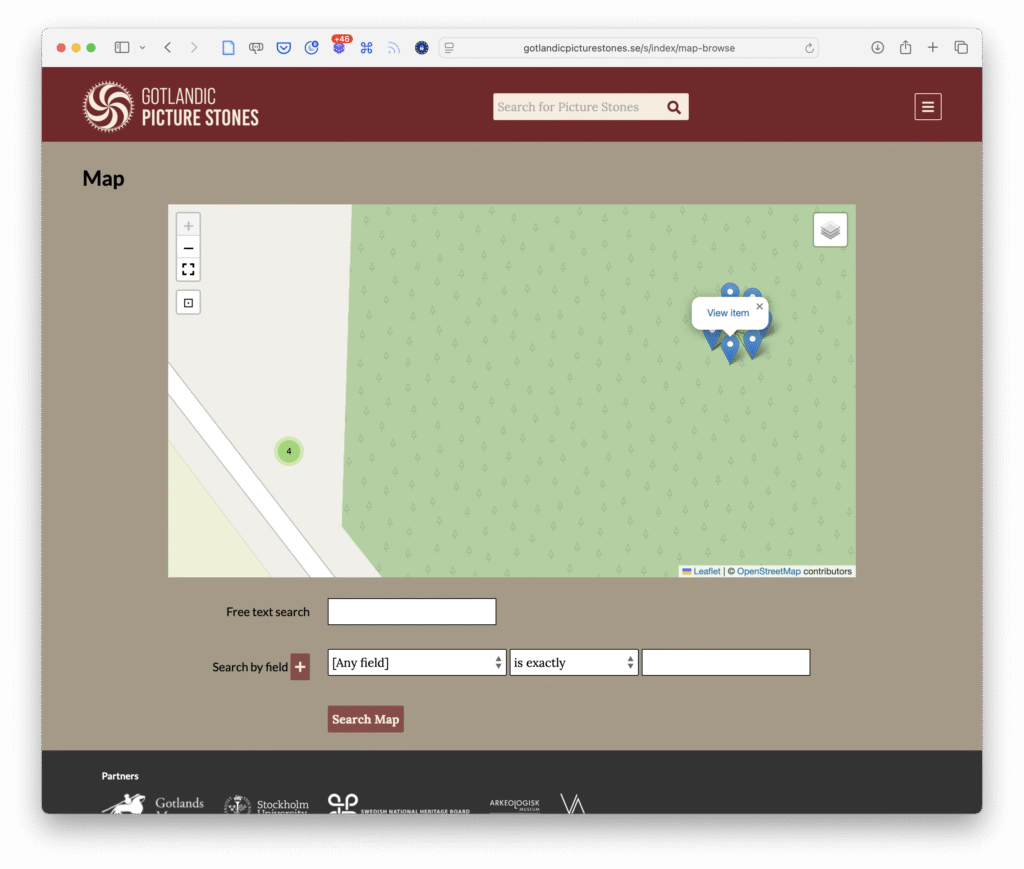
Inzoomat läge. Skärmbild.
Inte heller det inzoomade läget är genomarbetat. Leaflet erbjuder möjlighet att anpassa kartnålarnas popuprutor. Istället för ”View item” hade det passat bra med titel och bild redan här, så att besökaren inte behöver klicka för att se om hen hittat rätt bildsten på kartan.
Fortsättning följer?
Sammantaget återstår alltså en hel del arbete med att anpassa gränssnitt och åtgärda en del skavanker i den digitala presentationen av vad som i grunden är ett fantastiskt digitiseringsprojekt. Vad har hänt?
Det är tydligt att projektets fokus varit själva digitiseringen av bildstenarna, inte den digitala förmedlingen av det färdiga resultat. Det kan inte ha funnits särskilt mycket tid, pengar eller engagemang kvar till arbetet med sajten.
I ljuset av Larissas artikel i förra nyhetsbrevet – Ser du mig fortfarande? Webbsidornas roll i AI-söktjänsternas tid – kan det vara värt att fundera över webbplatsens roll i forskningsförmedling av det här slaget. Istället för att lägga tid på att fixa till webbplatsen (mina anmärkningar är trots allt på marginalen, innehållet är värdefullt och går att ta del av) kanske det i första hand gäller att stärka upp presentationen av bildstenarnas metadata som maskinläsbar länkad öppen data.
Kanske allmänheten ändå tar del av databasens innehåll genom en LLM?
ChatGPT har full koll på den nya databasen……och kan även hämta detaljerad information om enskilda bildstenar.
Hur lär vi oss arbeta med digitalt kulturarv egentligen? Vi som jobbar med digitala metoder och verktyg inom kulturarvssektorn har ofta kombinerat en ”vanlig” humaniorautbildning med självstudier, arbetslivserfarenhet och kurser i digital humaniora. Både när det gäller fortbildning för redan anställda och utbildning av framtidens experter inom digitalt kulturarv har det hunnit dyka upp en hel del spännande satsningar.
Fortbildningsinsatser i museisektorn
De flesta som arbetar i museisektorn har, misstänker jag, plockat upp sina digitala färdigheter och kunskaper på jobbet och fritiden snarare än inom högskoleutbildningen. Flera försök att formalisera och generalisera den här typen av fortbildning pågår dock.
Det digitala museilyftet är inne på sluttampen. Det kommer bli intressant att ta del av resultat och utvärdering av denna jättesatsning på fortbildning för museianställda, tyvärr begränsat till personal vid stockholmsbaserade centralmuseer.
”Vanliga” kurser inom digital humaniora (jag läste några hösten 2020 och har tagit emot masterstudenter i digital humaniora som praktikanter) är ofta inriktade på textbearbetning snarare än museernas mer spretiga kombination av föremål, fotografier och metadata.
De gånger jag tagit emot praktikanter från utbildningar i digital humaniora har de oftast blivit glada över att ta sig an ett mer spretigt material än de sjok av samtida text de oftast får öva på i utbildningen. Det är också ett utmärkt sätt för oss som redan är etablerade i museisektorn att få en inblick i vad som ingår i högskoleutbildningarna idag, och dessutom en chans att vara top of mind när duktiga, nyexade kulturarvsarbetare ska söka jobb och börja använda sina kunskaper inom digitalt kulturarv. Ta emot praktikanter!
Men digital humaniora är inte allt. Äntligen börjar det dyka upp kurser på högskolenivå för den som vill jobba med digitalt kulturarv.
I höst erbjuder Lunds universitet en högskolekurs på 7,5 poäng med rubriken ”Digitalt kulturarv”. Den verkar innehålla både teoretiska och praktiska moment, samt en crash course i digitaliseringens mediehistoria. Mer information hos Lunds universitet.
Även Göteborgs universitet ger en intressant 7,5-poängskurs i höst, ”Digitala metoder och kulturarv”. Till skillnad från kursen i Lund är denna på distans och går i 25 %-takt över hela hösten, och kanske därför lockar en del museianställda som vill fortbilda sig. Mer information hos Göteborgs universitet.
På de mer generella musei- eller kulturarvsutbildningarna förekommer förstås digitala inslag, ofta i form av gästföreläsare som redan är verksamma i sektorn. Jag är glad över att den typen av gästspel nu kompletteras med fördjupande kurser! Förhoppningsvis kan vi återkomma i höst med mer detaljer från kurserna när de väl är igång.
Det går också att fortbilda inom digitalisering i mindre skala. Ett positivt exempel är Norrbottens museum, som tillsammans med ABF Norr ordnade en tretimmarskurs i fotodigitisering i Kalix den 1 april. Kanske något att prova för fler museer eller arkiv? Om du eller din institution har provat något liknande är jag nyfiken på att höra hur det gick!
Historiska likheter
Till vardags forskar jag om datorernas genombrott i Sverige, inte minst hur nya yrkesroller och utbildningsbehov växte fram runt datacentralerna och den digitala omställningen. Från att den första svenska elektroniska datorn togs i bruk 1953 dröjde det över tio år innan de första högskolekurserna i systemutveckling började erbjudas. Istället var det maskinvaruleverantörerna själva, statlig förvaltning, småskaliga privata utbildare och inte minst studieförbunden som tillsammans försökte tillfredsställa efterfrågan på utbildad arbetskraft som kunde använda den nya tekniken. Även vid persondatorernas genombrott under tidigt 1980-tal var det många olika institutioner och aktörer som hjälptes åt med kunskapsspridning. Jag tror verkligen att det finns utrymme för fler än bara högskolorna att jobba med fortbildning och kunskapslyft kring digitalisering även idag. Kunskap och färdigheter kring datorer och digital teknik har alltid behövt kombineras med kunskap inom de ämnesområden där datorerna ska användas, vilket gäller även digitalt kulturarv.
Har jag missat några spännande fortbildnings- eller utbildningsinitiativ inom digitalt kulturarv? Hör gärna av dig, så kan jag komplettera eller följa upp i kommande artiklar!
AI-tjänster som ChatGPT och Microsoft Copilot förändrar inte bara våra arbetssätt. De påverkar också hur vi tar till oss information på nätet. Allt fler klickar sig aldrig vidare till en webbsida, som vi gör när vi söker i en söktjänst som Google. Hur påverkar det webbsidorna och deras synlighet?
För de flesta kulturarvsorganisationer spelar webbsidan en relevant roll i deras kommunikation med publiken. Många har antingen där en söksida till deras samlingar eller så använder dem en extern tjänst som också är en webbsida. Vi delar viktig information där, från öppettider till evenemang och utställningar. Det har blivit mer än ett visitkort som man delar med en besökare. I många fall finns det så mycket information på en webbsida att det krävs medvetet UX-design och en genomtänkt struktur, för att inte tala om allt vi har gjort inom SEO (Search Engine Optimization), för att folk ska faktiskt hitta till vår webbsida.
Men spelar det egentligen någon roll längre? De senaste månaderna har fler och fler påpekat att vår användning av AI-tjänster som ChatGPT och Microsoft Copilot faktiskt leder till att färre klickar sig vidare till webbsidor. Svaret på frågan man ställer är idag för många inte längre ett Google-resultat med massa länkar som själv behöver välja emellan – utan kommer i form av löptext. Även Google-resultatet har förändrats och ger dig idag i många fall ett sammanfattat svar av informationen tjänsten har tillgång till.
I en artikel i MIT Technology Review kallade deras chefsredaktör Mat Honan denna utveckling för den ”största förändring i hur söktjänster har levererat information till oss sedan 1990-talet” (länk till artikeln). Förändringen består å ena sidan av att vi i allt mindre utsträckning använder oss av nyckelord i vårt sökande (”tekniska museet öppettider”) utan av frågor i naturligt språk (”När har Tekniska öppet idag?”) som ställs antingen som i form av text eller som som röstmeddelande. Å andra sidan får vi ett sökresultat som kan beskrivas som ett samtal (även kallad conversational search). Detta påskyndas av att AI-tjänster som ChatGPT nu även kan söka på webben live.
Som jag skrev innan är detta paradigmskifte inte bara något som sker i AI-tjänster, utan påverkar också existerande plattformar. Google började redan år 2023 att generera svar i löptext på sökförfrågningar. Meta levererar nuförtiden AI-svar på frågor som du har om dina grupper eller flöden på Facebook och Instagram (”Vem var det som nyss sålde Ölandssten i min loppisgrupp?”).
Förändringen ses också som hotande, som en del av en ”zero click”-framtid. En framtid där ingen någonsin behöver klicka sig vidare till en webbsidan, utan får all information i sitt samtal med tjänsten. Det finns olika effekter i denna framtid att reflektera över: Hur det påverkar oss om vi alla får information individuellt paketerad (anpassad till vår politisk inställning och samhällsbubbla) istället för att ha gemensamma referenser att diskutera, att de som är beroende på webbtrafik som inkomstkälla blir av med sin inkomst, hur hela den här webbannonsbranschen påverkas. För att inte tala om att AI gärna hittar på ett svar om den inte hittar relevant information.
Men vad betyder det för organisationer som arkiv, museer och bibliotek samt vårt ekosystem av kunskapsorganisationer? Som vanligt är svaret: Det beror på. Vilken roll spelar din webbsida egentligen i organisationens kommunikationsstrategi? Om det mest handlar om att besökaren vill veta mer om din verksamhet är det kanske inget jätteproblem. Då kommer du kanske bara behöva lägga mer vikt på att kommunicera den allra viktigaste informationen så strukturerad och vänligt för externa tjänster som möjligt. Fokuset framöver ligger då kanske mest på att renodla webbsidan och göra den mest relevanta information så lätt att hitta som möjligt. Största utmaningen blir kanske att verifiera att svaren som publiken ställer om din organisation och verksamhet i olika andra tjänster blir rätt. En annan utmaning blir det för organisationer där man på grund av kostnaderna och riskläget blockerar olika AI-botar. Detta kan också påverka ens organisations synlighet och informationsflöde mot nya söktjänster.
Mer problematiskt kan det bli om du faktiskt har en webbsida som vill skapa engagemang på själva webbsidan. Jag minns att jag lyssnade på ett museum för mindre än ett år sedan som hade precis blivit klart med sin nya webbsida, ett projekt som hade kostat mycket pengar och tagit mycket tid. Man hade optimerat bland annat för att leda fler besökare till själva webbsidan. Är det en statistisk mätpunkt som kommer att minska i relevans? Kommer vi behöva lägga mindre vikt på webbsidornas utveckling i våra kommunikationsbudgetar?
Det största problemet ser jag faktiskt för de delar av nätet som är beroende av webbtrafiken för inkomst och levnad. Jag tänker till exempel på Wikipedia och dess systerprojekt. Just nu bygger projektets modell på att fler engagerar sig, skriver och förbättrar artiklar, dinera pengar via den där pop-up-en en gång per år. I och med att Wikimedia-innehållet är fritt tillgängligt har det blivit en relevant del av den data som olika AI-tjänster tränats på. Vi ser redan att några språkversioner av Wikipedia går ned i sidvisningar, för att deras innehåll dyker upp i svaren hos ChatGPT, Copilot och Claude. Samtidigt hänvisar dem inte nödvändigtvis till källan. Man hamnar alltså aldrig på den där Wikipedia-artikeln. Vem upptäcker då att det finns fel i artikeln, eller att den måste uppdateras? Hur genererar gemenskapen nya medlemmar? (se denna artikel i The Observer)
Det är frågor som en centralisering av webben och nätsöket ställer oss framför, en gammal men fortfarande aktuell fråga: Hur når vi samhället med vår kunskap så effektivt som möjligt – och vad kräver det från vår sida?
Det är ingen hemlighet att både jag och Larissa uppskattar Wikipedia och Wikimediarörelsens olika plattformar. Larissa presenterade tre strategier för Wikimedia-samarbeten i vårt första nyhetsbrev och jag tänkte nu komplettera med ett lite mer hands on-betonat inlägg om bilduppladdningar, nämligen hur det går till att ladda upp bilder till Wikimedia Commons med hjälp av verktyget OpenRefine.
Bakgrund
Genom åren har svenska kulturarvsinstitutioner använt en del olika verktyg för sina bilduppladdningar till Wikimedia Commons. Det allra mesta är uppladdat i samarbete med Wikimedia Sverige, med hjälp av en serie skript i programmeringsspråket Python. Det har krävt en hel del handpåläggning och specialanpassning för varje ny uppladdning. Några museer har använt det mer användarvänliga verktyget Pattypan, som dock inte uppdaterats på tre år.
Sedan 2023 går det att använda OpenRefine för att ladda upp bilder till Wikimedia Commons. OpenRefine liknar Excel eller andra kalkylbladsprogram, men innehåller en mängd extrafunktioner för bearbetning och anpassning av data.
Under våren 2025 håller jag på att ta fram en färdigpaketerad workshop så att fler på museer och arkiv kan lära sig ladda upp filer till Wikimedia Commons utan att behöva ta in extern hjälp. Hittills har detta bland annat resulterat i att Göteborgs konstmuseum laddat upp ett antal 1400- och 1500-talsgravyrer och målningar.
Den process jag beskriver nedan passar bäst för ett mindre urval bilder, det vill säga det Larissa kallar ”Step by step, bit by bit”. Större uppladdningar med tusentals filer går också att göra genom OpenRefine, men då är det bra att ha genomfört ett gäng mindre uppladdningar först för att lära känna både OpenRefine och Wikimedia Commons ordentligt.
Denna guide kommer att uppdateras löpande. Håll till godo med denna första, ofullständiga version och kom gärna med kommentarer!
Dator (mac/windows/linux) och internetuppkoppling (gärna stabil sådan).
Installera OpenRefine, som går att ladda ned på https://openrefine.org/download. Uppladdningar till Wikimedia Commons stöds sedan version 3.7.
Om du vill hämta information från Wikimedia Commons, inte bara ladda upp, bör du också installera OpenRefine-tillägget CommonsExtension.
När du startar OpenRefine öppnar programmet en flik i din webbläsare med adressen http://127.0.0.1:3333.
Samlingsinformation som behövs för att komma igång
Datastruktur i samlingsdatabaser skiljer sig åt, men oftast går det att exportera information i kalkylbladsformat. Ju mer utförlig information desto roligare, men minimikraven för uppladdningar till Wikimedia Commons är följande:
Själva bildfilen
En skapare/upphovsperson
Någon slags datumangivelse
Någon slags bildbeskrivning
En upphovsrättslig status/bildlicens
Se till att exportera informationen inklusive själva bildfilens filnamn inklusive filändelse (till exempel ”bild.jpg”) i ett kalkylark. Ett kalkylark med information och en mapp med bildfiler är det som behövs för att påbörja arbetet med uppladdningen.
Bildfil
Flera vanliga filformat (bland annat jpg, png och tif) går bra att använda.
Skapare/upphovsperson
För kulturhistoriskt foto räcker det med fotograf. För fotografier av konstverk eller museiföremål bör både konstnär/föremålsskapare och fotograf finnas med.
Datum
Det behövs en tidsangivelse för när ett fotografi är taget eller ett konstverk är skapat. Det går att ange datum i fritext, som intervall och liknande, men någon slags information behöver anges.
Bildbeskrivning
Varje uppladdad bild behöver en kort beskrivning. En kortversion av beskrivningen (till exempel ett konstverks titel eller motivet i ett kulturhistoriskt fotografi) används med fördel även i filnamnet på Wikimedia Commons.
Kolumner i OpenRefine som behövs för att ladda upp
Importera samlingsinformation i OpenRefine genom att skapa ett nytt projekt. Kontrollera att kolumner och rader ser rimliga ut.
De kolumner som behövs för att genomföra en uppladdning är:
Lokalt filnamn med fullständig sökväg
Beskrivande filnamn att använda på Wikimedia Commons
Frivilligt: datum, skapare och motiv som strukturerad information
Wikitextfält som innehåller beskrivning och upphovsrätt/licens. Om datum, skapare och motiv inte finns som strukturerad information behöver de anges i wikitextfältet.
Lokalt filnamn
För varje bildfil som ska laddas upp behövs det fullständiga filnamnet inklusive absolut sökväg. (På Windows något i stil med C:\Documents\Mapp\Mapp\bild.jpg, på Mac snarare /Users/användarnamn/Mapp/Mapp/bild.jpg.)
Beskrivande filnamn till Wikimedia Commons
Bildfiler på Wikimedia Commons bör ha beskrivande filnamn. Jag brukar rekommendera en struktur i stil med ”Beskrivning, Museum, Inventarienummer.filändelse”. Det är obligatoriskt att ange filändelse (dvs .jpg, .tif eller liknande).
Vissa tecken är förbjudna i filnamnen på Wikimedia Commons. Till exempel kommer kolon (:) att ersättas med bindestreck (-) vid uppladdning, så det är bättre att undvika specialtecken i filnamn.
Information om skapare, tillverkningsdatum, motiv, avbildade personer och liknande går att ladda upp i form av strukturerad data.
Wikitext
En minimal wikitextmall ser ut på följande sätt:
=={{int:filedesc}}==
{{Information
|description = {{sv|beskrivning}}
|date =
|source =
|author =
}}
=={{int:license-header}}==
lämplig bildlicens eller information om utslocknad upphovsrätt
Bearbetning av data i OpenRefine
Information i OpenRefinekolumner kan bearbetas på en mängd olika sätt, med språken GREL, Python eller Clojure. Jag rekommenderar GREL och använder det i exemplen nedan. OpenRefines GREL-dokumentation finns även under fliken. Ett antal färdiga GREL-kommandon (”recept”) för vanliga åtgärder.
Filnamn med sökväg
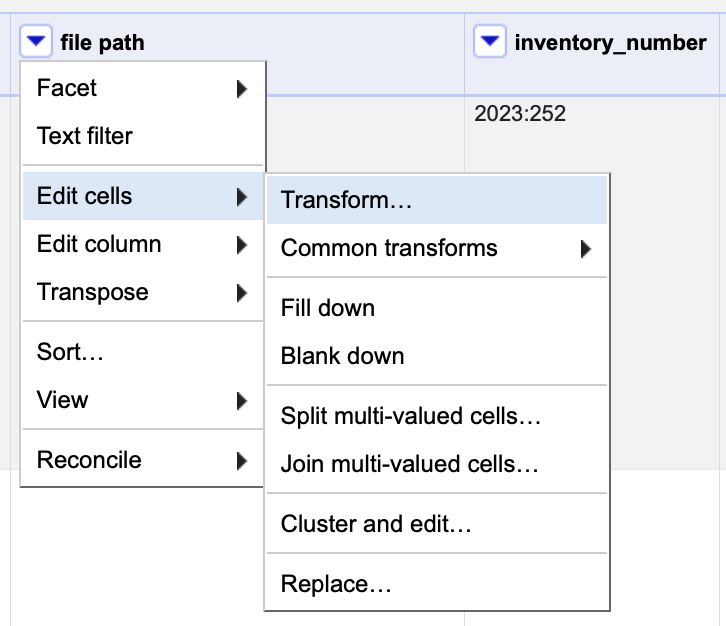
Den kanske vanligaste bearbetningen är att kombinera textsträngar med information från en kolumn. I exemplet ovan innehåller kolumnen ”file path” bara filnamnet, men jag vill att den ska innehålla den absoluta sökvägen till filen (vilket krävs för bilduppladdning).
Varje kolumn har en nedfällbar meny med alternativet ”Edit cells” → ”Transform…”. En fast textsträng (i det här fallet sökvägen till den mapp filerna ligger i) inom citattecken går att kombinera med kolumnvärdet med ett plustecken. Den bearbetade kolumnen kommer därmed att innehålla den fullständiga sökvägen till filen.
Beskrivande filnamn till Wikimedia Commons
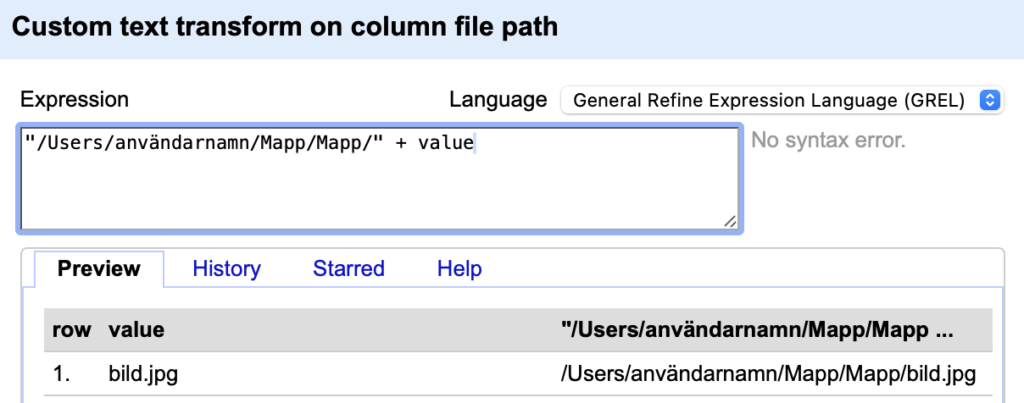
Ett beskrivande filnamn skapas på liknande sätt. Förslagsvis kombineras fält för titel/kort beskrivning med museinamn och inventarienummer. För att hämta värdet i en annan kolumn än den du utgår ifrån, använd cells["kolumnnamn"].value.
Rekonciliering av strukturerade data
Konceptet ”Strukturerade data på Wikimedia Commons” innebär att bildfiler kan beskrivas med hjälp av länkade öppna data-tripletter där subjektet är en filpost på Wikimedia Commons medan predikat och objekt hämtas från Wikidata. Exempelvis kan ett fotografi beskrivas på följande sätt: M161876210P170Q4950863, det vill säga ”Foto på linbanan över Torneå älv” ”har skapare” ”Mia Green”.
”Rekonciliering” i OpenRefine innebär att ett fritextfält matchas mot strukturerad data. I exemplet ovan ska alltså fotografnamnet ”Mia Green” bytas ut mot en länk till Mia Greens wikidataobjekt. Läs igenom Wikidatas hjälpsida om rekonciliering. Även OpenRefine har en (ännu längre) hjälpsida om rekonciliering. Rekonciliering sker mot Wikidata om inget annat är valt, och det är lämpligt att göra klart all rekonciliering av strukturerad data innan du fortsätter till nästa steg.
Rekonciliering av filnamn
Även det tilltänkta Wikimedia Commons-filnamnet behöver rekoncilieras, det vill säga kontrolleras mot Wikimedia Commons så att det inte redan är upptaget.
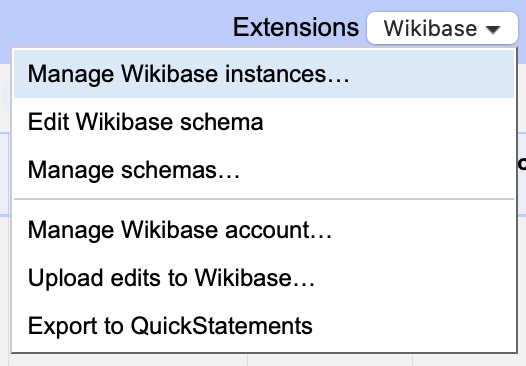
Först måste Wikimedia Commons väljas som wikibaseinstans.
Välj Wikimedia Commons. All fortsatt rekonciliering och uppladdning sker nu mot Wikimedia Commons istället för mot Wikidata. Om du behöver rekonciliera ytterligare mot Wikidata behöver du byta tillbaka dit.
Förberedning av Wikibaseschema
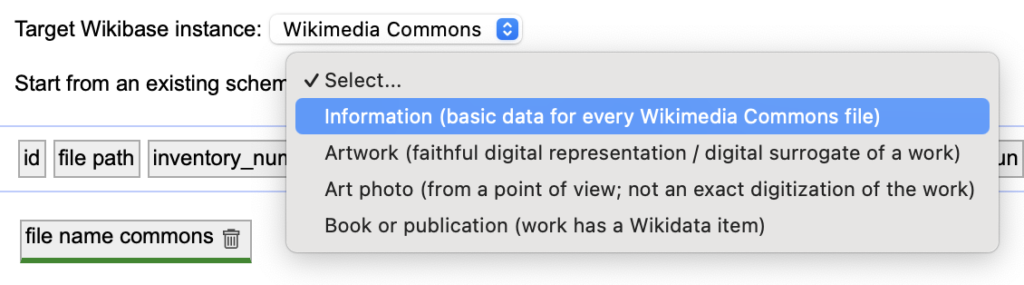
Innan uppladdningen går att genomföra behöver kolumnerna i OpenRefine slutligen matchas mot de fält som behöver fyllas i på Wikimedia Commons. Detta görs genom ett så kallat ”Wikibaseschema”, som hittas i övre högra hörnets meny under ”Edit Wikibase schema”.
OpenRefine tillhandahåller mallar för de vanligaste uppladdningstyperna. För konstverk passar Artwork-mallen bra men för kulturhistoriskt foto rekommenderar jag Information-mallen.
För att kunna ladda upp filer behöver du vara inloggad på Wikimedia Commons. I övre högra hörnet av OpenRefine-fönstret finns en meny med alternativet ”Manage Wikibase account…” där du kan logga in.
Hantera varningar
Kontrollera fliken ”Issues”. Om allt är rätt ifyllt finns bara en varning kvar, nämligen att du kommer att skapa ett angivet antal nya objekt på Wikimedia Commons.
[Här kommer det fyllas på med möjliga felmeddelanden och hur de kan hanteras]
Dags att ladda upp!
Själva uppladdningen sker också i Wikibasemenyn i övre högra hörnet, under menyalternativet ”Upload edits to Wikibase…”.
[Skärmdump på resultat från uppladdning]
Efter uppladdningen
Det kan vara bra att hålla koll på eventuella kommentarer från andra användare på Wikimedia Commons inklusive en del patrullerande skript (botar) som besöker nyuppladdade filer. Botar som upptäcker fel i filernas metadata (till exempel saknad licensinformation på grund av något misstag i schemainställningarna) kommer att lämna ett meddelande på din användardiskussionssida på Commons. Det kan därför vara bra att aktivera e-postaviseringar för redigeringar på diskussionssidan. På användarinställningarna på Wikimedia Commons under fliken ”aviseringar” är meddelanden om redigeringar på diskussionssidan den första raden bland kryssrutorna.
De flesta organisationer avväger väldigt noggrant om de ska skaffa sig ett konto i nya sociala medier. Har vi resurserna och rätt kompetens? Hur blir den här kanalen en relevant pusselbit i vårt kommunikationsarbete? Kan vi nå våra målgrupper där på andra sätt än på andra plattformar? Men egentligen borde vi också fundera på en annan aspekt: När är det dags att lämna?
Ibland bubblar diskussionen upp: Hur länge ska vi vara kvar? Ibland handlar det om Facebook, för att engagemanget minskar, för att man inte når ut som förr, för att plattformen inte är attraktiv för unga. Men just det senaste året har diskussionen handlat mer allmänt om de amerikanska jättarna: Metas plattformar Facebook och Instagram samt Twitter aka X.
När plattformar förändras
Det var i januari 2025 som över 60 tyska universitet och forskningsinstitutioner gick ut med ett gemensamt meddelande att de skulle lämna plattformen X och uppmanade andra att följa dem. Argumenten var att värderingarna som de står för, bland annat frihet, faktabaserad vetenskap och mångfald, inte längre främjas på plattformen. I pressmeddelandet skrev institutionerna att de anser att en öppen och konstruktiv diskurs är avgörande för demokratin. Samtidigt beskriver de att just mekanismerna på X motverkar en sådan. De förespråkade att lämna plattformen, det vill säga att inte publicera innehåll längre. De flesta behöll sina konton passivt för att motverka att kontonamnen kan kapas. Samtidigt uppmanade organisationerna andra att följa dem till plattformen Mastodon, en decentraliserad tjänst som är en del som kallas för fediversum.
Twitter, eller X, var en speciell plattform (som jag uppriktigt kan sakna ibland) på så sätt att fokuset låg på mikrobloggar och korta textinlägg som man delade med andra. Plattformen var i Sverige jämförelsevis liten, kanske mest populär bland forskare, journalister och liknande yrkesgrupper. När Twitter fyllde tio år 2016 var det fortfarande bara runt sex procent av svenskarna som använde tjänsten dagligen. Även om många organisationer och myndigheter i Sverige har eller hade konton på plattformen var den aldrig så relevant som i andra länder, där museer och kulturorganisationer hade egna strategier eller blev kända för sitt innehåll på Twitter. Att lämna plattformen kan därför kännas som mindre dramatiskt, när man inte överger en kanal eller en gemenskap man har byggt i flera år. Men det kan kännas mycket svårare att lämna Instagram eller Facebook.
Ett läge utan alternativ?
Ett problem är såklart att, även om man kommer fram till att en plattform inte längre överensstämmer med ens värderingar eller inte ger det engagemang man hoppades på, att det i många fall inte finns några givna alternativ. I Twitters fall resulterade plattformens förändring i ökad användning av ett flertal nyare tjänster med liknande fokus på mikroblogginlägg, som Bluesky, Threads och Mastodon. Men när vi tittar på Instagram och Facebook når ingen annan tjänst ens i närheten av deras maktkoncentration. I en artikel i The Guardian intervjuades professor Jeannie Paterson som är direktör för Centrum för AI och digital etik vid University of Melbourne. Artikeln handlade om huruvida man borde lämna Metas plattformar efter Metas beslut i januari 2025 att inte längre faktagranska innehåll på Facebook och Instagram.
Ett citat hängde kvar i mitt minne efter jag läste artikeln: ”In a perfect world, people who were unhappy with Meta’s decision would walk away from Instagram. But in the real world that’s a lot harder to do. It’s a real community of sort of small and independent creators… And that’s how they bring their products to the wider community.” Hon fortsatte senare med: ”It’s just not possible to set up an alternative at this point in time. So, to put it bluntly, we’re in a bit of deep shit, to be honest.” Jag tänkte på det när jag såg olika upprop de senaste månaderna att lämna Instagram och Facebook för decentraliserade alternativ som Pixelfed. Vi som ger tjänsterna vår uppmärksamhet är ju den valuta som skapar marknadsvärdet för företag och organisationer att satsa på en plattform – eller inte. Vi som användare gör alternativen möjliga – eller inte.
Jag tänker ofta på den makt som kunskapsorganisationer, myndigheter och kulturarvsinstitutioner har. För fem år sedan hade jag lätt sagt att museer, arkiv och bibliotek ska finnas där användarna är. Och i det stora hela står jag fast vid det. Men när det gäller vilka företag vi väljer att stödja är jag inte längre säker. Genom våra annonspengar, genom trovärdigheten vi ger till en plattform genom vår närvaro och vårt innehåll ger vi dem också ett kapital som vi kanske borde vara mer restriktiva med.
Att det inte finns givna alternativ gör funderingar inte enklare. Men jag tror att många kulturarvs- och forskningsinstitutioner just nu borde fundera på vilka röda linjer de vill sätta upp. Hur länge ska vi vara kvar? Hur mycket kan företagen avvika från vad vi säger att vi står för innan vi behöver agera? Vilken sorts engagemang gör det värt det att stanna på en plattform? Särskilt statliga, regionala och kommunala myndigheter borde ställa sig frågan om skattepengar ska användas för att få uppmärksamhet via kampanjer och annonser. Aron undersökte just detta närmare; under 2024 betalade de svenska museimyndigheterna cirka 4,5 miljoner för annonsering i sociala medier, främst till Meta.
I alla dessa tankar har jag ofta dragit nytta av att följa Carl Heath, som på Mastodon och LinkedIn delar med sig av reflektioner över sitt arbete och sina tankar. Jag avslutar denna artikel med ett citat från ett av hans inlägg om sociala medier:
”I Sverige har vi länge värnat om vår digitala infrastruktur genom investeringar i bredband och hårdvara. Men vår digitala offentlighet, de platser där samtal och opinionsbildning sker, har vi överlämnat till ett fåtal globala aktörer. […] Vi kan inte längre behandla dessa digitala plattformar som triviala. De är våra nya torg, våra tidningar, våra caféer och våra mötesplatser. De bör formas av samma värderingar som vi applicerar på andra samhällsbärande infrastrukturer.”












{kind=link}